
CQA Knowledge Crowdsourcing
[Introduction] [Expertise Identification] [Expertise Characterisation] [Implementation] [Resources]
Crowdsourcing Knowledge Acceleration in the Case of Collaborative QA Systems
Introduction
Context: We take collaborative question answering as an important type of knowledge crowdsourcing. In this case, the requestor is the asker, the worker is the answerer, and the task is question answering. In knowledge crowdsourcing, task features and worker features are essential for knowledge generation. Specific to the case of collaborative question answering systems, the first component of our study is to understand the manifestation of user expertise, and the difference between user expertise and activeness in CQA systems.
Understanding the nature of these features is of fundamental importance to drive the economy and prosperity of this class of knowledge crowdsourcing systems. In addition, it provides referential insights for other classes of knowledge crowdsourcing systems such as those in enterprises.
Motivation: Existing studies in CQA systems mostly view these two user properties as equal to each other: user activeness and expertise. For instance, following metrics have been used for expertise measurement: #answers, #answers-#questions (or normalised version), or metrics highly correlated with #answers (e.g., reputation in Stack Overflow). For active systems like Stack Overflow, which adopts effective gamification mechanisms, this might not be suitable since some users are highly engaged in the game of answering to questions. Starting from this motivation, we propose an expertise metric Mean Expertise Contribution (MEC) [P.1], which is the first metric that eliminates the effect of user activeness on expertise measurement.
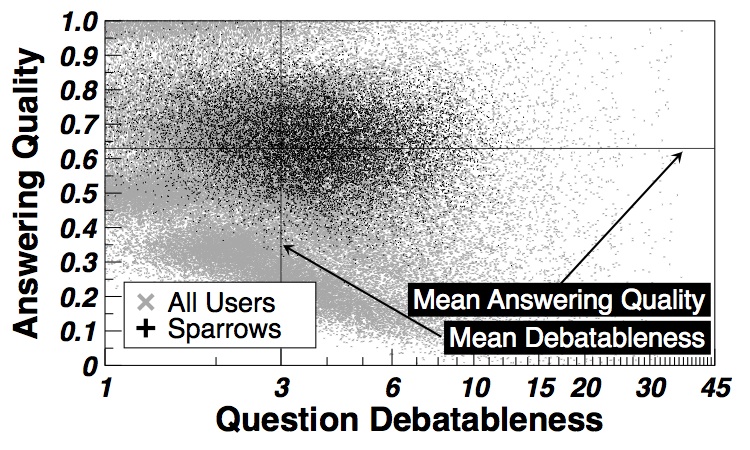
Expertise Identification
The graph above visually demonstrates our motivation. Highly active users with #answers>=10, which we define as 'sparrows', do not always provide high quality answers.
Novel metric: The definition of MEC takes advantage of the rich user voting's in Stack Overflow, viewing voting's as crowdsourced social judgements of answer qualities. This definition conforms to the way of how expertise is defined in social science: skills/knowledge recognised by the public or peers.
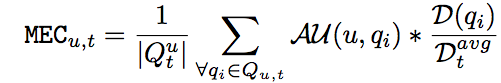
AU is the utility of the answer provided by user u to question q; we define it as the inverse of the rank of the answer (according to the amount of received votes) provided by u for question q. D is the debatableness of the question q, calculated as the number of answers.
One of the most important factors in MEC formula is the normalisation to #answers, i.e., activeness does not equal to expertise. This metric provides a method to approximate expertise (as we will see in the next section), based on which we can further distinguish the manifestations of expertise and activeness.
Using MEC, we define a group of users with MEC>=1 as 'owls', as an approximation of experts. We conduct a comparative study to characterise the performance and behaviours of these two group of users, which correspondingly, help us to understand the contributions and behaviours of these two groups of users.
Expertise Characterisation
Performance: The following two plots show the contribution of owls and sparrows in terms of quantity and quality. Higher resolution can be obtained by right clicking a plot and select 'open in new tab/window'.
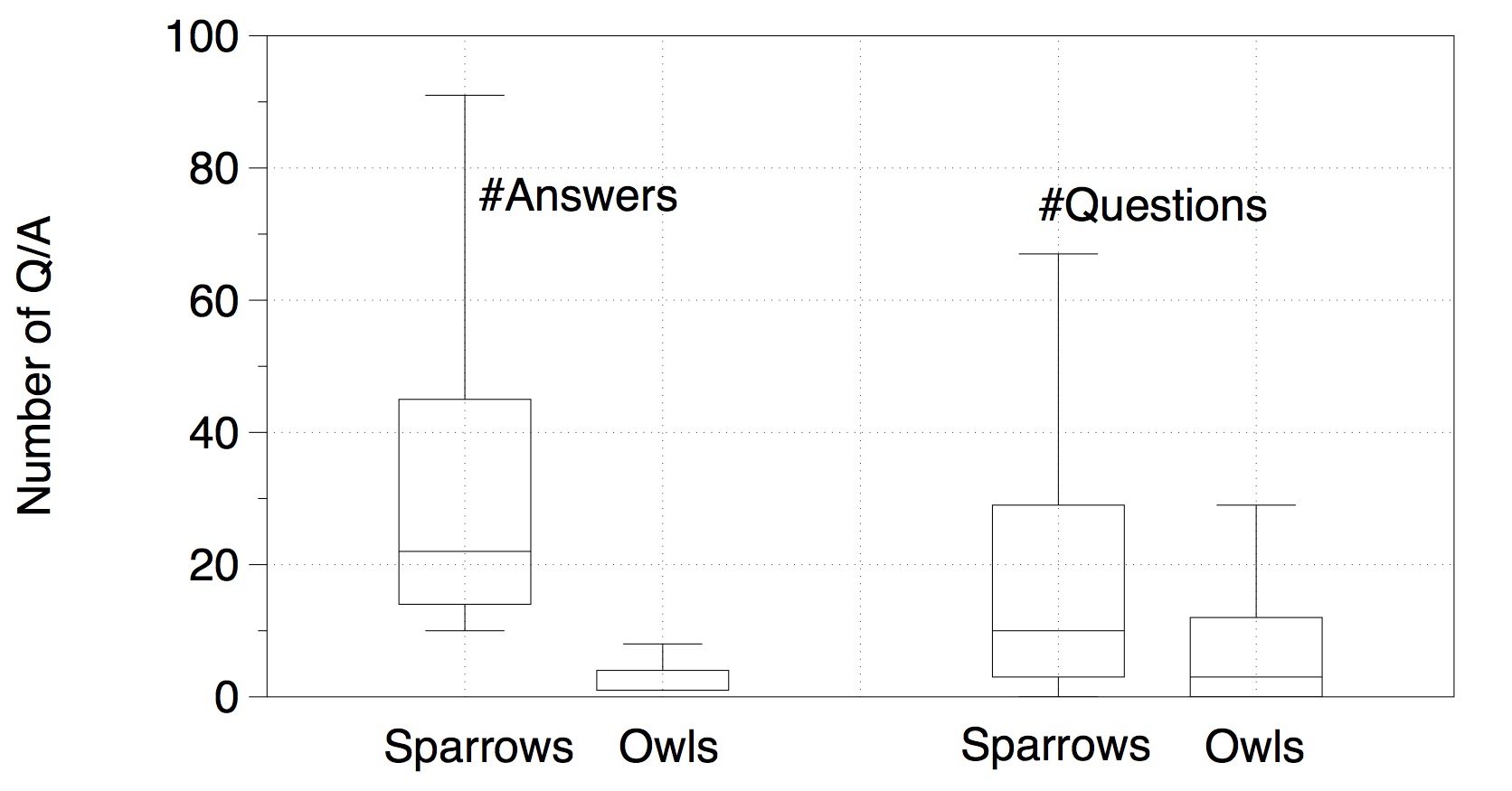
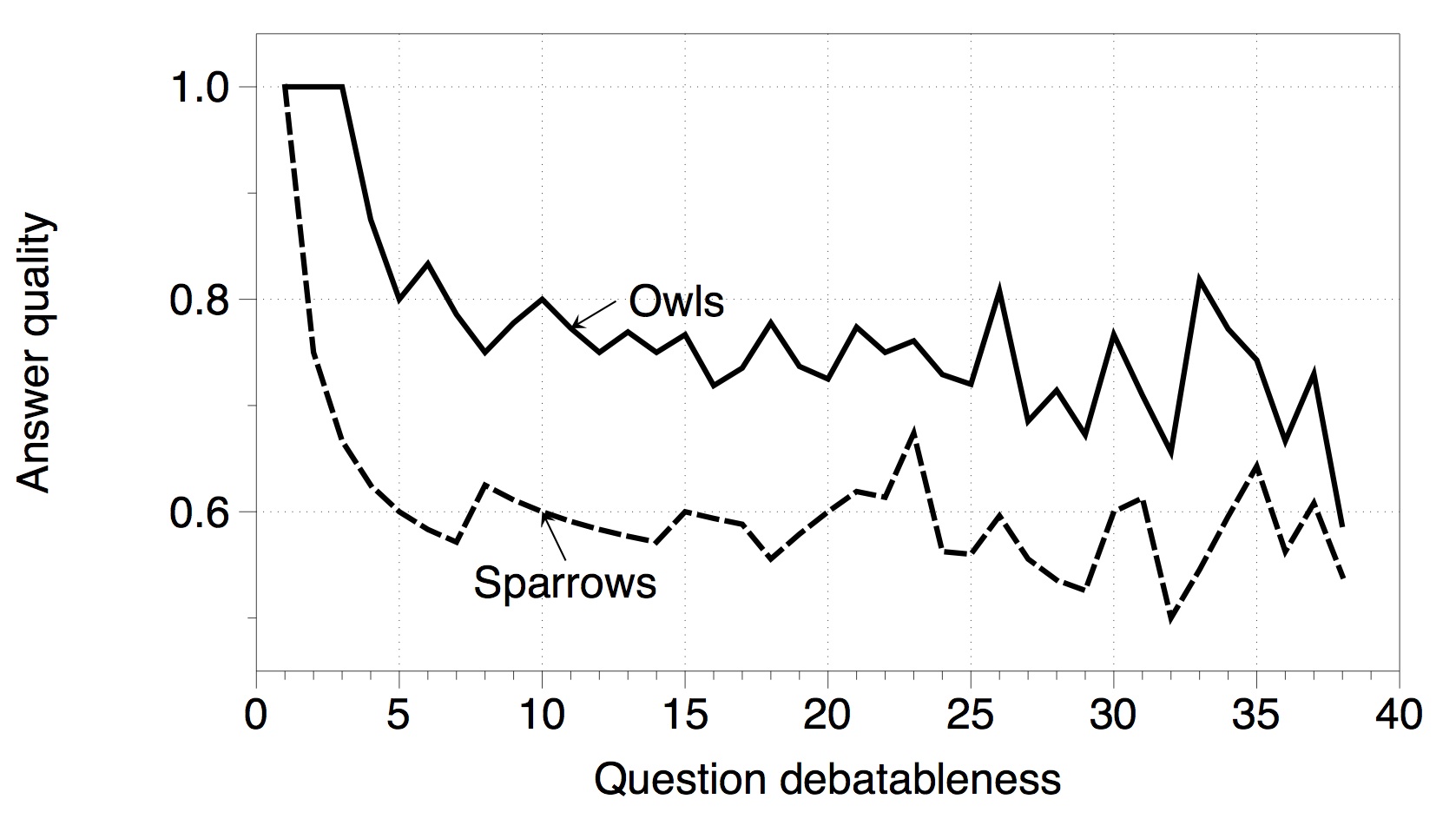
As shown above, owls are less active however offer better answers than sparrows. The answering quality in the right plot above aggregates questions according to the number of answers (defined as debatableness in the paper). A more in-depth experiment shows that, if the comparison is refined to per-question level instead of per-group (according to debatableness) level , answers provided by owls are still better than that by sparrows: for those questions answered by both groups, there are 69K questions to which owls's answers rank higher, while only 18K that sparrows' answers are better.
 Can we select the best subset of users that historically provide highest-ranking answers? This is computationally difficult. Instead, comparing two existing groups of users in terms of answering quality is much easier: select the common questions both group of users answered, then compare their rankings. Therefore an expertise metric could be a promising solution, for defining a new group of users as a better approximation of experts. We made a first try of new expertise metric that eliminates the effect of user activeness in paper.
Can we select the best subset of users that historically provide highest-ranking answers? This is computationally difficult. Instead, comparing two existing groups of users in terms of answering quality is much easier: select the common questions both group of users answered, then compare their rankings. Therefore an expertise metric could be a promising solution, for defining a new group of users as a better approximation of experts. We made a first try of new expertise metric that eliminates the effect of user activeness in paper.
Behaviour: Another objective of our work is gain qualitative insight of the behaviours of users of different expertise and activeness. We find that, in addition to the difference of contribution between sparrows and owls, they also show difference preference in 1) answering to questions, and 2) posting questions. Moreover, owls are less driven by incentivisation. Following two plots show the popularity (#views) of the questions answered (left) and posted (right) by sparrows and owls. Complete results can be find in our paper [P.1].
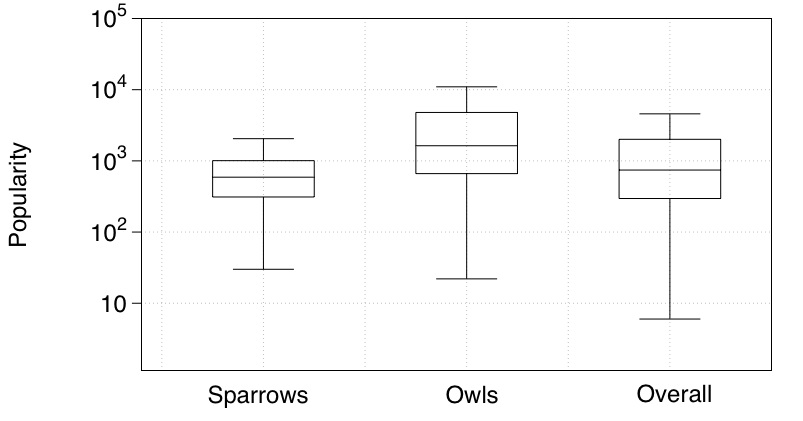
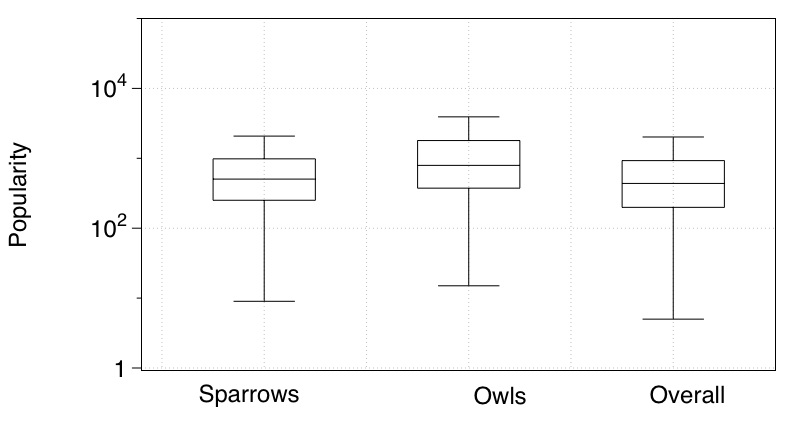
To replicate the results (including the above two figures), you can try out our code on the publicly released data set.
Implementation:
Dataset: We use the public dump of StackOverflow data released in September 2013. The newest version can be accessed at archive.org [D.1]. Note that the size of the data is big:~16G in compressed format.
Scripts: Importing the original xml data to database can largely accelerate the data processing procedure. You can find in the last section our script [C.1] for extracting data into database, and building temporal tables. Note that we use postgres. It can be easily changed to mysql, as the interfaces are the same.
Code: The code for MEC calculation and result generation can be downloaded in the last section [C.2]. Result data will be generated into the directory 'data', intermediate data will be put into directory 'temp_files'.
Apart from our own implementation, we provide an implementation of MEC in StackExchange Data Explorer, based on Jon Ericson's initial implementation [L.1]. The modified implementation can be accessed in the last section [L.2]. we handle the ranking ties of answerers with the same answering score in a way that, the ties are broken by ranking the user with earlier registration higher.
Working Notes: Stack Overflow users raised a very inspiring discussion [L.3] on this work. As we point out in the section Expertise Identification, filtering the optimal subset of users is hard, whereas iteratively improving over existing metrics is possible. The metric MEC shows promising result in filtering high expertise users without the influence of user activeness, we are now working on quantifying question difficulty to further refine this metric.
Resources
P=Publication, D=Dataset, C=Code, L=Link.
[P.1] Jie Yang, Ke Tao, Alessandro Bozzon, Geert-Jan Houben. Sparrows and Owls: Characterisation of Expert Behaviour in StackOverflow. In Proceedings of the 22nd International Conference on User Modeling, Adaptation and Personalization, Aalborg, Denmark, July 7-11, 2014, p. 266-277, 2014, Springer LNCS. [pdf]
[D.1] https://archive.org/details/stackexchange
[C.1] https://wis.st.ewi.tudelft.nl/umap2014/files/Scripts.zip
[C.2] https://wis.st.ewi.tudelft.nl/umap2014/files/Code.zip
[L.1] Jon Ericson's initial implementation
[L.2] http://data.stackexchange.com/stackoverflow/query/219875/mec-revised?tag=c%23