[About] [Example scenarios] [Datasets] [Publications]
About
In the last few years, Twitter has become a powerful tool for publishing and discussing information. Yet, content exploration in Twitter requires substantial effort. Users often have to scan information streams by hand. In this line of research, we approach this problem by means of faceted search. We propose strategies for inferring facets and facet values on Twitter by enriching the semantics of individual Twitter messages (tweets) and present different methods, including personalized and context-adaptive methods, for making faceted search on Twitter more effective. We conduct a large-scale evaluation of faceted search strategies and reveal significant benefits of those strategies that (i) further enrich the semantics of tweets by exploiting links posted in tweets, and that (ii) support users in selecting facet value pairs by adapting the faceted search interface to the specific needs of a user.
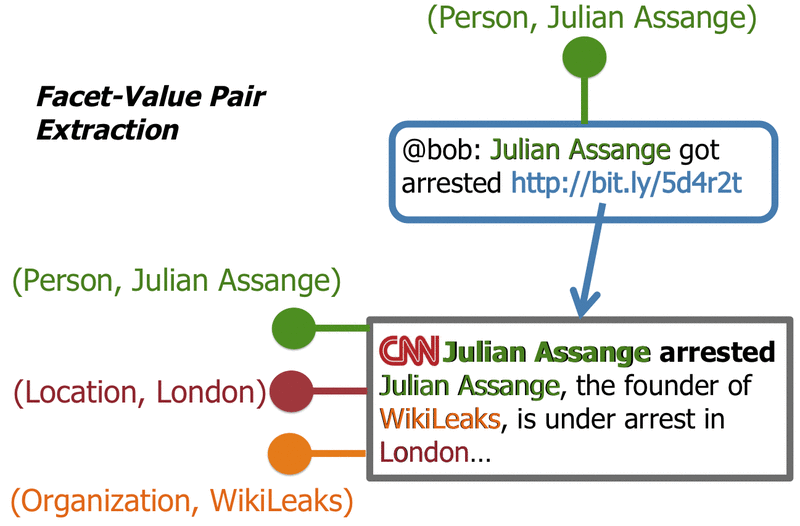
To provide an intuition of our facet value pairs, consider the example below. Given the content of Twitter messages, we extracted facet-value pairs (typed entities) to better understand the semantics of Twitter activities. Therefore, we utilized the OpenCalais Web service. Furthermore, we:
- followed the links posted in those Twitter messages,
- extracted the main content of those referenced Web pages using BoilerPipe by Christian Kohlshuetter, and
- also extracted facet-values from the external Web pages so that
- the facet-value pairs extracted from the referenced external Web resources can be used to further describe the semantics of a tweet.
(a more detailed explanation is available here)
Example scenarios
Within ImREAL, such faceted search facilities are particularly useful at simulation design time when simulation developers are brainstorming the plot of the simulation, the focus of the simulation and the particular training aspects. A search on Twitter can reveal what particular aspects of a task provide difficulties to many users, a fact of great interest to simulation developers. However, due to the sheer number of tweets published each minute it is impossible to scan them all. Faceted search offers one possibility to reduce the number of messages that require a human reader's attention, by allowing the simulation developer to filter on facets and ignoring all messages that are not in the sought-after facets.
Datasets
Tweets: Over a period of more than four months (starting from November 15th 2011) we crawled Twitter information streams of more than 20,000 users. Together, these people published more than 30 million tweets. We make a subset of this dataset available online.
Subset of our dataset available for download:
- tweets.sql.gz [643MB, 2316204 records] Sample of tweets processed with OpenCalais
- news.sql.gz [73MB, 77544 records] News articles monitored from 62 news media websites
- sementicsTweetsEntity.sql.gz [71MB, 1896328 records] Facet-value pairs extracted from tweets (1,051,524); 709,245 distinct entities (39 different facet types)
- sementicsNewsEntity.sql.gz [40MB, 1216570 records] Web resources (63,140), 170,577 distinct entities (39 different facet types)
Publications
- Fabian Abel, Ilknur Celik, Geert-Jan Houben, Patrick Siehndel. Leveraging the Semantics of Tweets for Adaptive Faceted Search on Twitter. In Proceedings of 10th International Semantic Web Conference (ISWC), Bonn, Germany, October 2011 [bib, pdf]
- Ilknur Celik, Fabian Abel, Patrick Siehndel. Adaptive Faceted Search on Twitter. In Proceedings of International Workshop on Semantic Adaptive Social Web (SASWeb), in connection with UMAP, Girona, Spain, July 2011 [bib, pdf]
- Ilknur Celik, Fabian Abel, Patrick Siehndel. Towards a Framework for Adaptive Faceted Search on Twitter. In Proceedings of International Workshop on Dynamic and Adaptive Hypertext (DAH), in connection with ACM Hypertext, Eindhoven, The Netherlands, June 2011 [bib, pdf]
