
1. Abstract
In the last few years, Twitter has become a powerful tool for publishing and discussing information. Yet, content exploration in Twitter requires substantial effort. Users often have to scan information streams by hand. In this paper, we approach this problem by means of faceted search. We propose strategies for inferring facets and facet values on Twitter by enriching the semantics of individual Twitter messages (tweets) and present different methods, including personalized and context-adaptive methods, for making faceted search on Twitter more effective. We conduct a large-scale evaluation of faceted search strategies and reveal significant benefits of those strategies that (i) further enrich the semantics of tweets by exploiting links posted in tweets, and that (ii) support users in selecting facet value pairs by adapting the faceted search interface to the specific needs of a user.
2. Adaptive Faceted Search Framework
Our adaptive faceted search framework allows for various strategies that adapt the faceted search interface to the interests and context of the user who is searching. The core building blocks of those strategies are:
- Basic Weighting Scheme: the core strategy to weight the facet-value pairs: occurrence-frequency
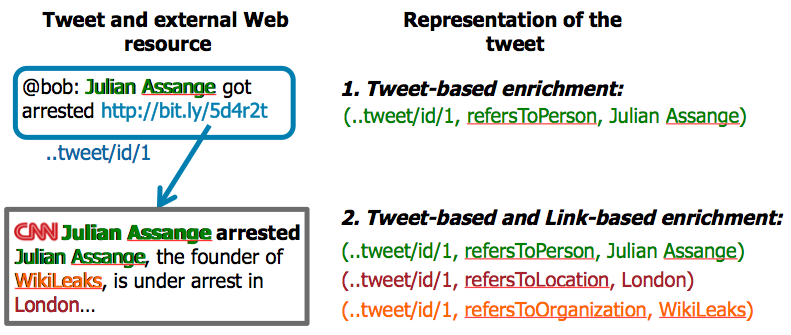
- Semantic Enrichment: enriching tweets to extract FVPs: (i) tweet-based enrichment and (ii) tweet-based and link-based enrichment (see figures below)
- Personalization: adapting the FVP ranking to the demands of the user that is modeled by some user modeling strategy: (i) personalized and (ii) non-personalized strategies
- Diversification: strategy to increase variety among the top-ranked FVPs: (i) diversification or (ii) no diversification
- Time Sensitivity: adapting the FVP ranking to temporal context: (i) time-sensitive and (ii) non-time-sensitive strategies
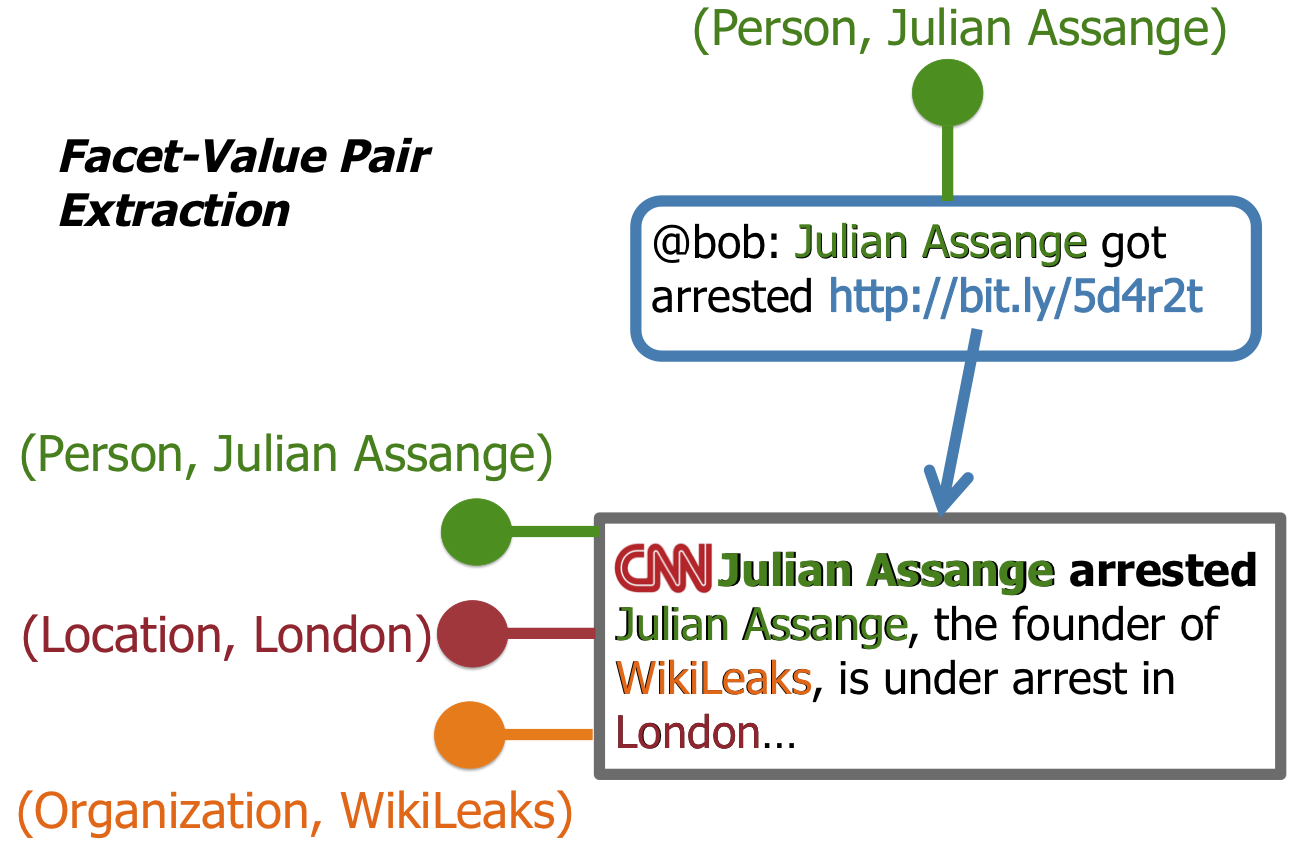
2.1 Semantic Enrichment: Facet-Value Pair Extraction
Given the content of Twitter messages, we extracted facet-value pairs (typed entities) to better understand the semantics of Twitter activities. Therefore, we utilized the OpenCalais Web service. Furthermore, we:
- followed the links posted in those Twitter messages,
- extracted the main content of those referenced Web pages using BoilerPipe by Christian Kohlshuetter, and
- also extracted facet-values from the external Web pages so that
- the facet-value pairs extracted from the referenced external Web resources can be used to further describe the semantics of a tweet.
The figure below illustrates this process:
2.2 Semantic Enrichment: Representing Twitter Messages
How should one represent the content of a Twitter message? As the semantics of a tweet's content are not explicitly specified on Twitter, the representation of a tweet may look as follows (using the SIOC vocabulary, cf. http://pegasus.chem.soton.ac.uk/):
<http://twitter.com/bob/statuses/109813827616>
a <sioc:Post> ;
dcterms:created "2010-03-24T14:23:06+00:00" ;
sioc:content "Paris supports Julian Assange http://bit.ly/6z2t9b" ;
sioc:has_creator <http://twitter.com/bob> ;
sioc:links_to <http://bit.ly/6z2t9b> .
However, such representations make it difficult to issue structured queries with respect to the
content of a Twitter message. For example, searching for tweets that refer to Paris Hilton
would require a like comparison on sioc:content
(e.g. ..WHERE { ?x sioc:content ?content FILTER regex(?content, "Paris Hilton")..).
With the semantic enrichment offered by our faceted search framework and in particular based on the facet-value pair
extraction described, it is possible to describe the semantics of a Twitter and therefore to allow for
structured (faceted search) queries:
<http://twitter.com/bob/statuses/109813827616>
a <sioc:Post> ;
dcterms:created "2010-03-24T14:23:06+00:00" ;
sioc:content "Paris supports Julian Assange http://bit.ly/6z2t9b" ;
sioc:has_creator <http://twitter.com/bob> ;
sioc:links_to <http://bit.ly/6z2t9b> ;
sioc:has_topic <http://dbpedia.org/resource/Julian_Assange> ;
sioc:has_topic <http://dbpedia.org/resource/London> ;
sioc:has_topic <http://dbpedia.org/resource/Paris_Hilton> .
Hence, given the tweet representation above one can issue structured faceted search queries. Our adaptive faceted search framework provides two core types of strategies for enriching the semantics of tweets. Those strategies impact the way tweets are represented as illustrated in the figure below:
2.3 Code
- Adaptive Faceted Search Framework: https://svn.st.ewi.tudelft.nl/wis/persweb/faceted-search-evaluation/
- User Modeling strategies: https://svn.st.ewi.tudelft.nl/wis/persweb/um-twitter-news/
Code can be checked out from SVN repository using the following credentials: user = iswc, password = iswc.
2.4 Documentation
JavaDoc:
Example A. Searching via a basic faceted-search engine:
//Create a basic faceted-search engine that ranks facet-value pairs (FVPs) based on
//occurrence frequency and that exploits links to further enrich the tweet representations:
boolean linkBasedEnrichment = true;
FacetedSearchEngine basic = new TwitterEngineInMemory_Frequency(linkBasedEnrichment);
//Search for Julian Assange:
Query facetedQuery = new Query();
facetedQuery.add(new FacetValuePair("http://s.opencalais.com/1/type/em/e/Person ", "Julian Assange"));
SearchResult matchingTweets = basic.search(facetedQuery);
Example B. Searching via a personalized faceted-search engine based on some user modeling strategy:
//Configure user modeling strategy that should be used by the personalized search engine:
Timestamp profileFrom = Timestamp.valueOf("2011-01-01 00:00:00");
Timestamp profileTo = Timestamp.valueOf("2011-06-24 00:00:00");
boolean linkBasedEnrichment = true;
UMConfiguration umConf = new UMConfiguration("My user modeling strategy", UM_Type.Entity_based, UM_Source.Twitter_based, profileFrom, profileTo, UM_TimeSlot.All, 1, null);
//Instantiate personalized search engine:
double influenceOfPersonalPreferences = 0.5;
FacetedSearchEngine personalized = new TwitterEngine_Personalized(influenceOfPersonalPreferences, umConf, false, linkBasedEnrichment)
//User with Twitter ID 14048484 searches for Julian Assange and London:
Query facetedQuery = new Query(14048484);
facetedQuery.add(new FacetValuePair("http://s.opencalais.com/1/type/em/e/Person ", "Julian Assange"));
facetedQuery.add(new FacetValuePair("http://s.opencalais.com/1/type/em/e/Location ", "London"));
SearchResult matchingTweets = personalized.search(facetedQuery);
3. Evaluation Framework for Faceted Search on Twitter
Our evaluation framework extends an approach introduced by Koren et al. (WWW '08) that simulates the clicking behavior of users in the context of faceted search interfaces. At the moment, the evaluation classes are packaged together with the faceted search framework.
3.1 Code
- Evaluation Framework: https://svn.st.ewi.tudelft.nl/wis/persweb/faceted-search-evaluation/
- Main class: de.l3s.sync3.faceted.simulation.Simulator
Code can be checked out from SVN repository using the following credentials: user = iswc, password = iswc.
3.2 Documentation
JavaDoc: Evaluating Adaptive Faceted Search (see particularly Simulator)
Example C. Evaluating a faceted-search engine:
//Create simulator and search engine that should be evaluated:
Simulator simulator = new Simulator();
FacetedSearchEngine basic = new TwitterEngineInMemory_Frequency(linkBasedEnrichment);
//Create search settings which the search engine has to tackle:
List searchSessions = ISWC_Evaluation.getExampleSearchSessions();
//Run simulations to evaluate the faceted search strategy and log results in a database:
simulator.runSimulationsOneTarget(searchSessions, basic, new MySQLFacetedSearchStatsLogger());
4. Datasets
Tweets: Over a period of more than four months (starting from November 15th 2011) we crawled Twitter information streams of more than 20,000 users. Together, these people published more than 30 million tweets. We make a subset of this dataset available online.
Subset of our dataset available for download:
| name | number of records | description |
| tweets.sql.gz (643MB) | 2316204 | sample of tweets processed with OpenCalais |
| news.sql.gz (73MB) | 77544 | news articles monitored from 62 news media websites |
| sementicsTweetsEntity.sql.gz (71MB) | 1896328 | facet-value pairs extracted from tweets (1,051,524); 709,245 distinct entities (39 different facet types) |
| sementicsNewsEntity.sql.gz (40MB) | 1216570 | facet-value pairs extracted from external Web resources (63,140), 170,577 distinct entities (39 different facet types) |